

Ricardo León
What differentiates us from animals? Some say, technology, arts, science. Or our capacity to look-ahead and plan (which is the same part of our brain that causes us anxiety – our pursuit of mindfulness is nothing else than returning to our animal state, but that is a topic for another time). For sure, we need to language and communication on this list.
It has been a complex and diverting journey, from when the first homo sapiens started to emit sounds to present day, where thousands of heterogenous languages are spoken worldwide, branching off from different common roots, with different alphabets. And they keep constantly changing. For example: If you were to travel in time and space to 17th century London, and you happened to bump into Shakespeare, you would probably have a tough time communicating with him. And that’s only 400 years ago.
My point is languages are complex. Can we expect computers to understand it, for better or worse, as we do? Until recently, this limitation restricted search applications to simple keyword search. But that has all changed.
Keyword Search is Not Enough
Here is where Natural Language Processing (NLP) comes into play. NLP, which is a branch of Artificial Intelligence that intends to understand and produce unstructured content in the form of spoken and written language.
Unstructured content does not have any format or pre-defined schema. It’s essentially free text. We humans are great at producing unstructured content. E-mails, messages, tweets, contracts, manuals, RPFs, you name it. It is estimated that 80%-90% of content is unstructured.
Knowledge, facts and meaning are embedded in this type of content, surrounded by extraneous data. So often, the problem in search applications is how do we find the needle in the haystack?
Traditionally, search engines have been keyword-based. For example, if you search for “dog sleeps on mat,” the following text is an expected result:
The dog stared at the window and barked. When he felt everyone was safe, he returned to his mat to continue sleeping.
But, if you search for “pet naps on rug,” this same text won’t be retrieved, as these words are not found.
Keyword-based search engines have worked well for decades, but then search requirements became more demanding. In addition, the amount of available data has grown drastically in the past years. To put this in perspective, according to Statista, 97 zettabytes of data will be produced in 2022. That’s over 26 billion gigabytes daily! By comparison, in 2010, only two zettabytes were produced. That’s a 50-fold increase within a dozen years.
Fortunately, we are currently witnessing an unprecedented period of technology evolution where synergies between artificial intelligence, big data techniques, and cloud computing are leading to innovative search solutions.
Google is clearly a leader in this space. By introducing constant innovations and breakthroughs, we can navigate colossal volumes of data on the internet to find precise results. But Google has spoiled us by making search simple, powerful and ubiquitous.
Hybrid Search with Knowledge Graphs and AI Models
Google’s algorithm has evolved rapidly, from the original 2003 Page Rank. While keyword search is still useful in many use cases, hybrid search models have evolved that provide smarter “cognitive” search capabilities.
The Google search bar has evolved into a question answering system, where users type in a question and expect a direct answer. One way of achieving this is through a Knowledge Graph, which you can read more about in my colleague Matt Willsmore’s blog.
But what if the answer to a query can’t be found in the Knowledge Graph? For the next evolution in its search capabilities, Google introduced state-of-the -art artificial intelligence models, such as BERT (and most recently MUM).
BERT, which stands for ‘Bidirectional Encoder Representations from Transformers,’ has truly revolutionized the NLP world. Its main breakthrough is a deeper language context understanding achieved by analyzing text sequence all at once, as opposed to sequentially from left-to-right or right-to-left. This has a profound impact because BERT can understand word and sentence meanings by creating numerical representations that capture their semantic essence.
What are Extractive Answers (AKA Google Featured Snippets)?
With this in mind, let’s talk about one of Google’s coolest features: Featured Snippets (or more generally, Extractive Answers). Extractive Answers contain punctual information that provides a direct answer to user queries, usually posed as questions, without the need of browsing to the result and finding the answer. All of this is powered by BERT and BERT-derived models.
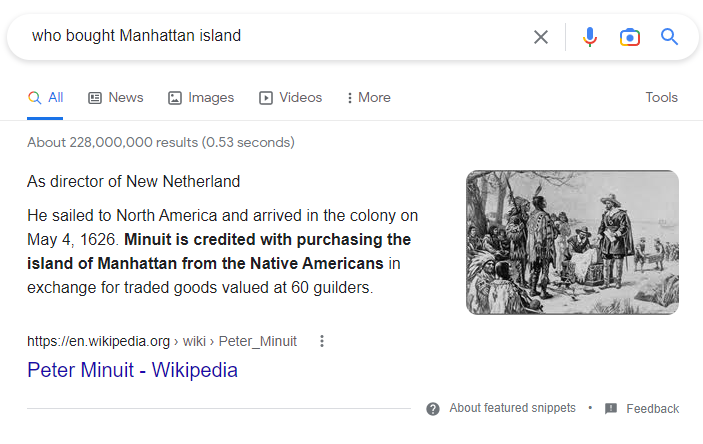
You probably have benefited from this feature without even realizing it. It is only natural that nowadays users want their enterprise search solutions to mimic what Google does. This is why we constantly hear “Just make it work like Google!” from our customers.

How does Extractive Answers work?
We leverage BERT and BERT-derived models as well as other technologies such as search engines, NoSQL databases and Knowledge Graphs databases, in conjunction with our Pureinsights Discovery Platform™, which is a robust cloud-based platform that performs advanced data processing and provides endpoints to expose results, such as featured snippets-like responses.
Let’s explore how BERT works.
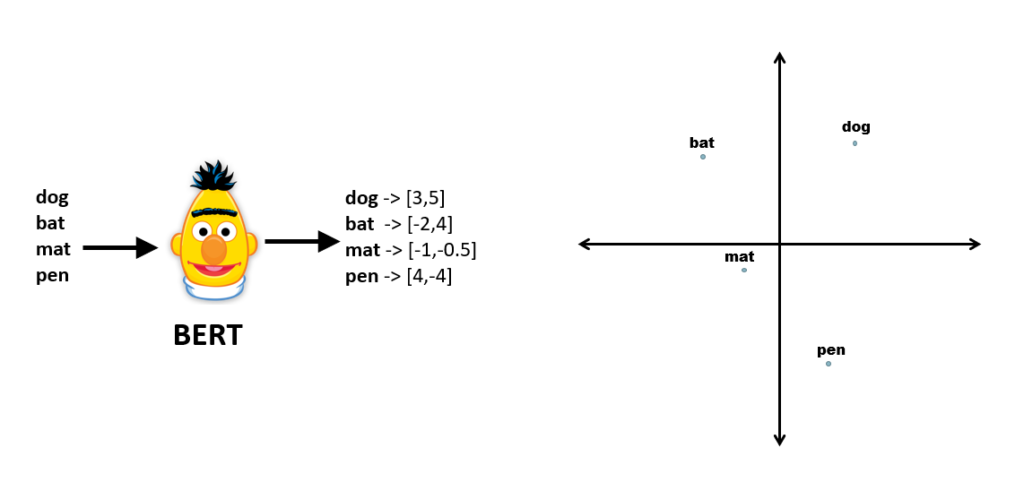
With BERT, it is possible to produce embeddings, which are numeric representations that contain the semantic essence of a block of text. For example, let’s assume we have very tiny BERT model that produces two-dimensional embeddings for single words, that is, an x,y coordinate system. If we were to produce embeddings for a few words, they would be spread across these two dimensions:
Now, let’s evaluate single words to produce its embeddings and find the closest related words in the above-mentioned space. Let’s try with the word ‘pet,’ and let’s visualize it in our imaginary two-dimensional world:
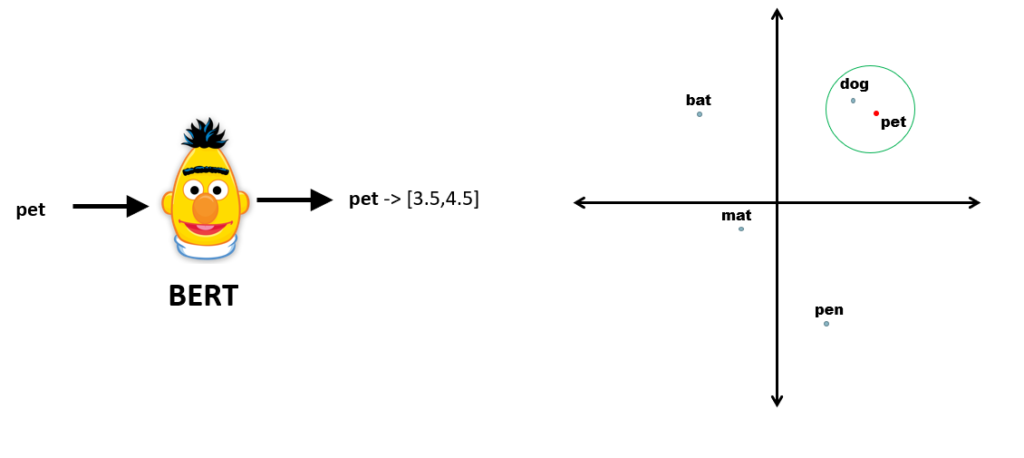
Because dog and pet are semantically related, their embeddings will end up close.
Now let’s do the same with the word ‘mat’:
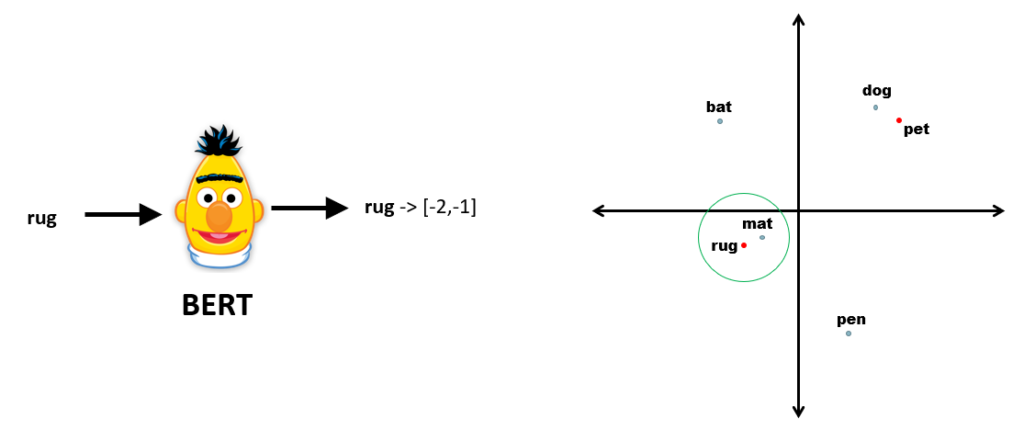
This is exactly what it is happens in featured snippets, except that embeddings are produced for chunks of unstructured text and not individual words. Also, BERT-models produce k-dimensional embeddings, with k being in the realm of hundreds or thousands. Even though that’s a level of dimensionality our brains cannot visualize, we can calculate semantic similarity using the same techniques as for two-dimensional spaces (for example: cosine similarity).
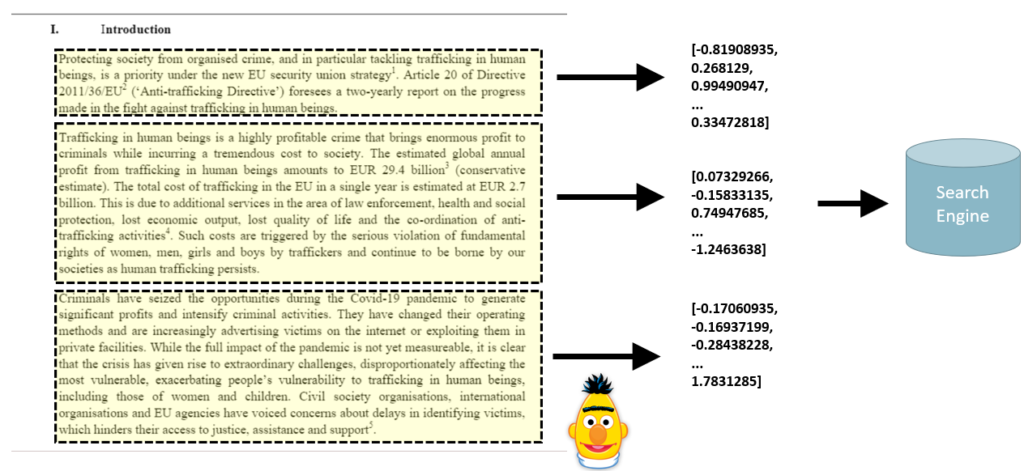
With the Pureinsights Discovery Platform™ (PDP), unstructured content is processed and divided into chunks, then for each chunk of text its k-dimensional embedding is produced. Both (chunk and embedding) are stored in a search engine.
Then, when performing a query in question form, an embedding is produced as well, which is compared against all embeddings in the search engine to produce a list of possible chunks that contain the answer.
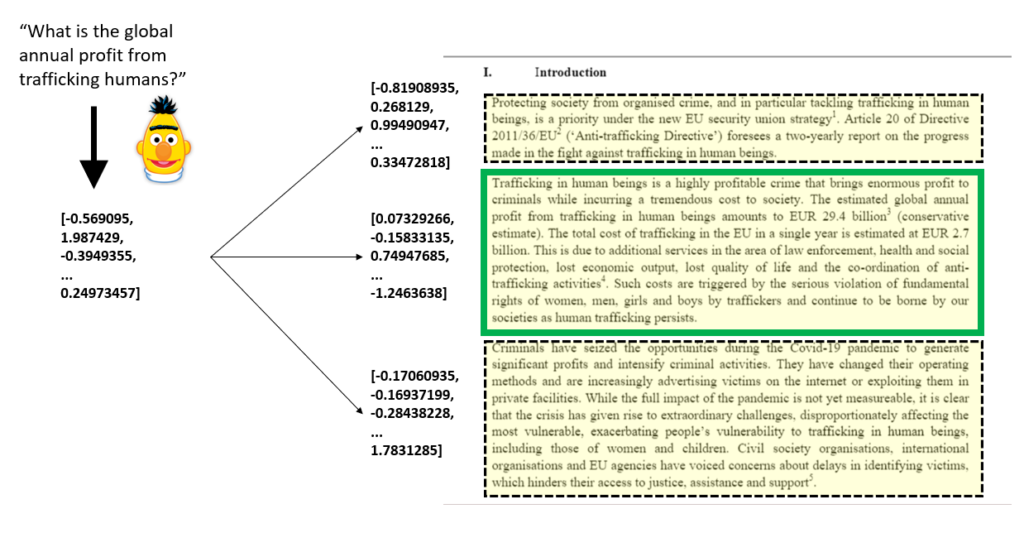
At this point we have identified a list of candidate chunks for various documents that are semantically close to the question. Essentially the haystack is groomed and reduced to specific places where the needle can be found.
Then using a BERT-derived question and answer model, the answer is located and pinpointed from the most suitable candidate. We have found the needle!

Extractive Answers: Actual Deployed Business Example
Extractive Answers have been customized and made available successfully to customers, such as the European Union Publications Office, which is the official provider of publishing services to all EU institutions, bodies and agencies. This organization handles all official information such as laws, regulations, research, open data, etc. The provided solution implements the described Extractive Answers approach plus additional customizations.
The EU has 24 official languages; therefore, all publications are made in most of them simultaneously. This Our Extractive Answers solution for the Publication Office employs BERT’s even employs a multi-lingual capabilities alongside other NLP techniques to allow for multilingual Extractive Answers without the need of translation.
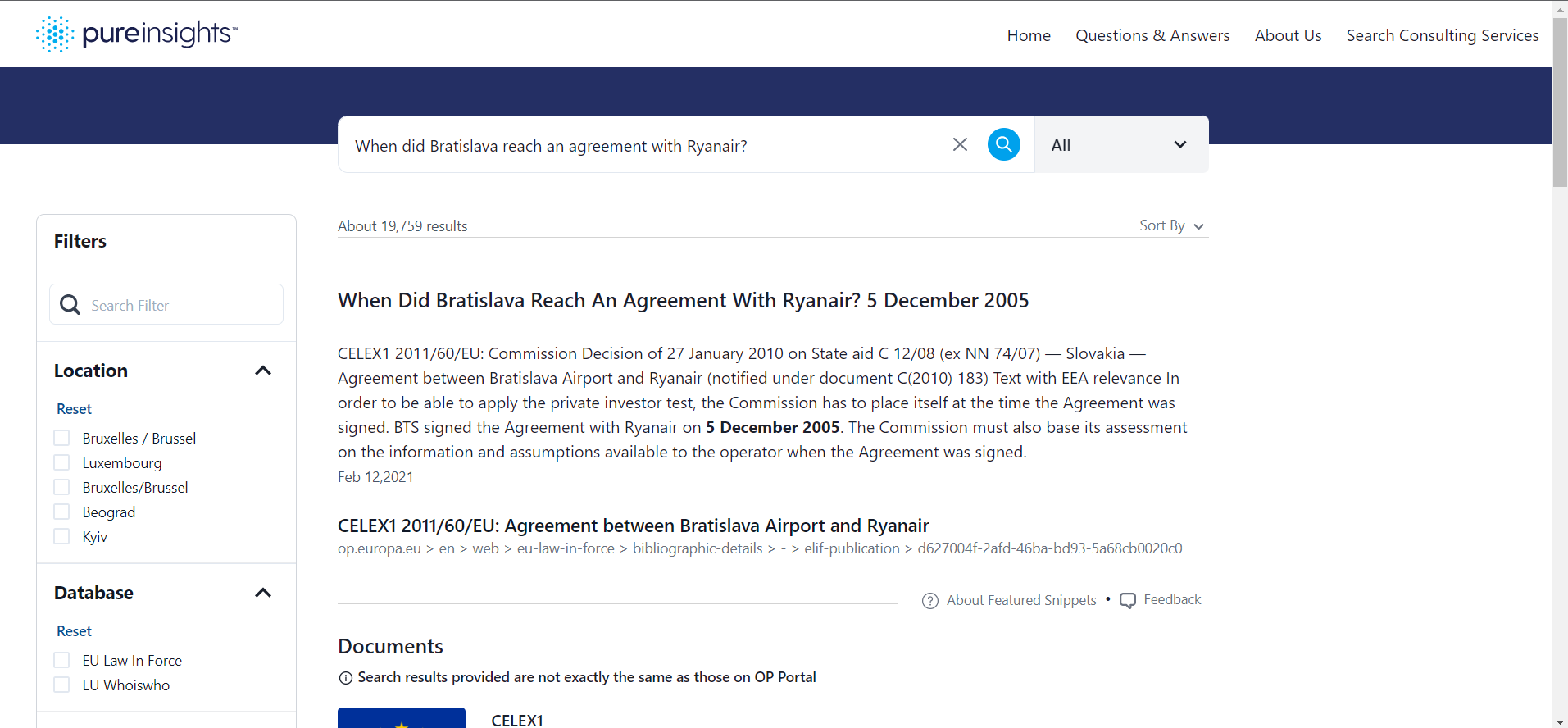
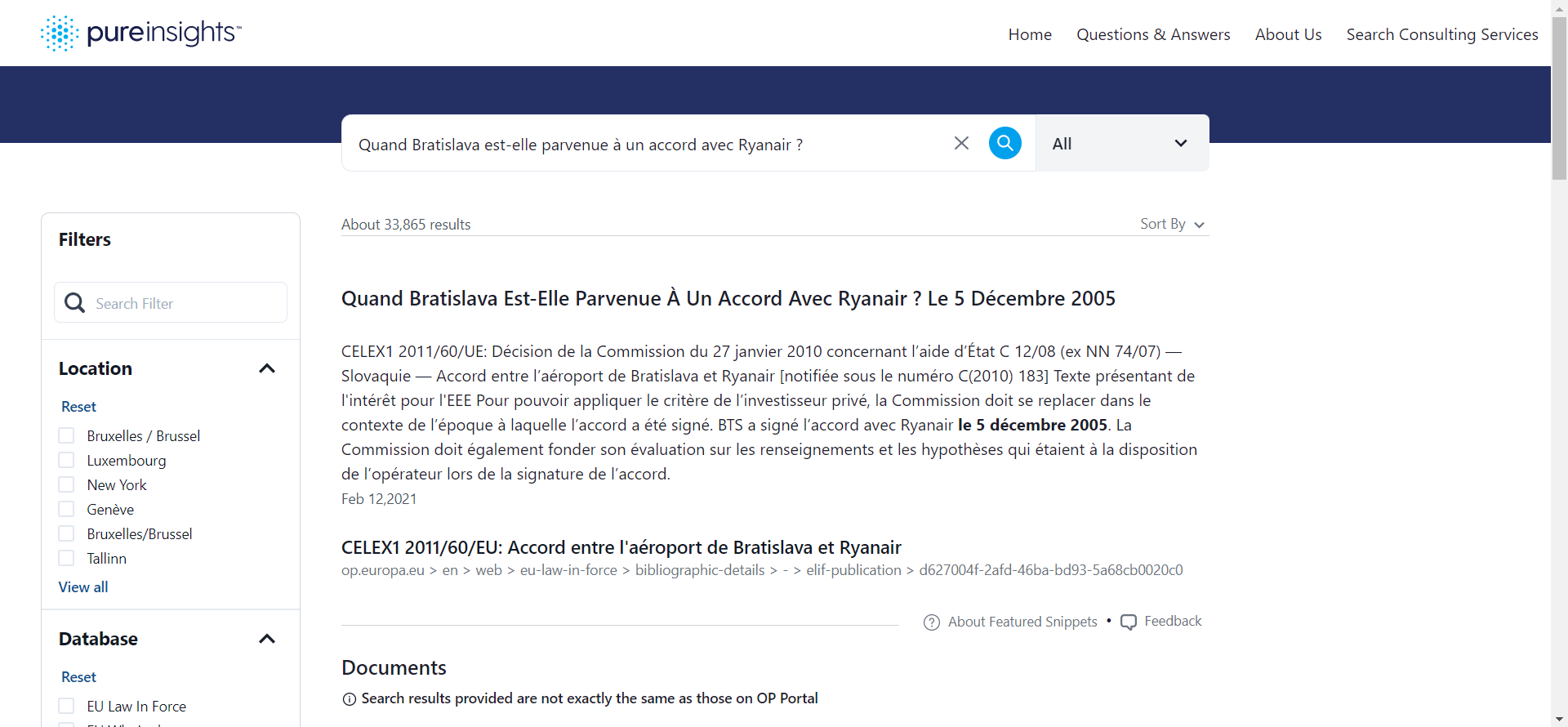
In the example below (in English and French), the question is posed “When did Bratislava reach an agreement with Ryanair?” The answer is “5 December 2005.” It does not reside in any database or Knowledge Graph. Rather it was “extracted” from an EU document. The paragraph and document reference it was extracted from is listed in the result and marked as a “Featured Snippet.”
Conclusion
It is definitely an exciting time for NLP and AI innovations. Enterprise search can benefit from these to provide Google-like experiences to customers and/or employees and to make the most of the valuable non-structured information stored in data warehouses, CMSs, CRMs, etc. Harnessing the power of NLP to provide robust enterprise search solutions such as Extractive Answers is here to stay.
If you were not able to catch my presentation on Extractive Answers at Enterprise Search & Discovery 2022, or you want to learn more about featured snippets / extractive answers, please feel free to CONTACT US at Pureinsights.
Pura Vida,
Ricardo