
Matt Willsmore

Third in a Three-Part Blog Series on Conversational Search
In this blog, we address the question “What are Large Language Models” (LLM’s), what different types are there and how they might evolve and impact the search engine market and search applications. The blog is the third in a three-part series on ChatGPT, GPT-3.x and Large Language Models. We hope the blogs can summarize these fast-changing developments in AI and offer pragmatic advice on the evolution of search interfaces to benefit from the opportunities these advances afford.
What is a Large Language Model?
Large Language Models are deep learning models that can represent, translate, generate and classify text based on previously seen ‘real’ text. The ‘large’ in LLMs refers to three main aspects. Firstly, the number of parameters (the internal values of the model that are set and optimized by training), secondly, the sheer volume of data the models are trained on, and thirdly the amount of computing power required to train the models. It is the advent of an ample supply of the third (computing power) that has led to our ability to create models with massive amounts of data and parameters in a reasonable space of time. Essentially, a few years ago Moore’s Law took us to a tipping point whereby LLM’s became possible, and now there is a new type of Moore’s Law equivalent where more data and parameters leads to better and better language models.
So how large are we talking? Seriously massive! GPT-3.5 which ChatGPT is based upon was trained with 175B parameters, which required 800GB of storage. It was trained on at least 75TB of text data, and the servers are reputed to have 8 high-end Nvidia A100 GPUs each. But they can be even bigger, for example Google’s PaLM model has 540B parameters, and WuDao 2.0 is reputed to have 1.75 Trillion parameters.
The rumor mill around GPT-4 has suggested it has 100 trillion parameters, a claim dismissed by Open AI who have not yet disclosed its size. However, although the relationship between model size and capabilities is not linear, there is a clear correlation between size and capability, and so we can expected LLM’s to continue to grow, at least for the short term. A bubble chart below illustrates the relative sizes.
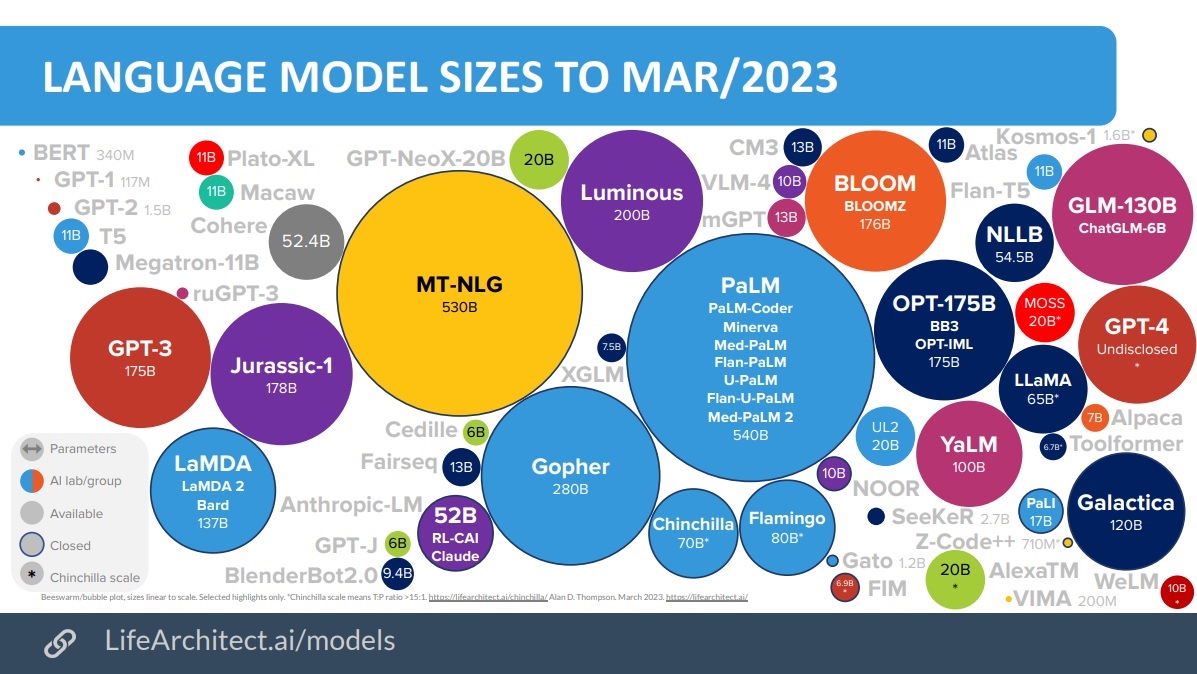
Source: Inside language models (from GPT-4 to PaLM) – Dr Alan D. Thompson – Life Architect
What different types of LLMs are there?
LLM’s are often referred to synonymously as transformers because at a high level, this is what they do: take an input and turn it into a specific type of output.
Take the example of English to French translation; the input is an English sentence and it is transformed into a French one. From there, we can see two broad classes of LLM: encoders and decoders. There are some complexities here, but putting it simply, an encoder is a transformer that’s used to represent the input in a different way. For example BERT, one of the original and certainly most ground breaking LLM’s, essentially converts text to an array of vectors. This can then be used for a variety of purposes such as similarity/semantic search.
A decoder model on the other hand, takes text as an input and outputs whatever it thinks comes next. In the case of ChatGPT, this is some form of chat response, but it could also be a search box autocomplete or a French version of some English textual input. These are often called generative models. Some models use both encoder and decoder approaches combined.
Language models have been around since the 1950s, and there has been a steady progress towards today with the invention of the Recurrent Neural Network (RNN) in the 1980s and the innovation of representing documents as a collection of word vectors in the early 2000s , but the modern era of pre-trained LLM’s started when BERT was made publicly available by Google in 2018. The paradigm shift was the fact that these models were pre-trained and generally transferable. This meant it was no longer necessary to find and collate massive datasets, become a machine learning expert, and find and pay for a supercomputer to get your hands on a useful model!
The intervening 5 years since BERT’s release have seen an explosion of innovation in this area resulting in many thousands of variants of models being made available, sometimes commercially, but often Open-sourced and free to use. For example, Hugging Face, one of the most popular repositories, has over 120k models, a fair proportion of which are LLMs. Often these LLM’s have been trained or fine tuned for a specific language domain such as Finance, Pharmacology or Toxic language so they can do a better job at whichever task they have been applied to.
There are also some commercial companies inventing LLM’s who have made a bit of a splash such as OpenAI (as you may have noticed), but also Anthropic, Cohere, Character.AI & AI21. Outsourcing the hosting, updating and serving of these large models is likely to be attractive to the many, many businesses who want to take advantage of this NLP revolution, but without having to worry about the details. It is still a pay as you go model though, so others will prefer to embed the Open Source versions (GPT-J anyone?) into their own platforms. This needn’t be a forbidding prospect because one of the big advantages of LLM’s is, as I’ve said, they’ve already been built! It can just be a question of a simple integration to start to take advantage of these new superpowers!
What LLMs are not.
It’s worth just stating it baldly: LLM’s are not an alternative to search. The fact that Bing and Google are going head-to-head might make it seem that way. Whilst they are very impressive, and an initial glance can be gob-smacking (especially if via the twitter hype-machine), it’s important to remember that LLM’s ‘just’ make stuff up. In fact, that’s all they do. This is especially true of generative models, but even encoders are just trying to approximate a representation based on probabilities. The stuff they make up might be correct, and often is. But it might not. It might just look convincing. And that’s dangerous territory for search. The big difference to remember is that search allows you to find something external that already exists (and is therefore hopefully not made up based on probabilities), whereas a LLM creates something new (possibly true, but possibly a hallucination).
Of course, the next big challenge for search engines is likely to be how to deal with potential misinformation being churned out by LLM’s…. but that’s a problem for another day.
What are LLMs used for?
The sweet spot for the latest cutting-edge LLM’s is Natural Language Generation (NLG). So, since it just came out a few days ago, in the spirit of investigation (and with a modicum of laziness) I asked GPT-4 to tell me ‘What are LLM’s used for?’ and this is what it said:

This seems pretty spot on to me, I can’t see any major omissions or errors, but then there is plenty of concrete info for it to base this on that would have formed part of its training data.
What about if we move into a more speculative realm?
I asked it:


Whilst GPT-4 was writing this for me, I completed some notes I’d started when planning this blog on what I would say to the same question, and GPT-4’s response was actually quite similar to mine, although perhaps a bit more comprehensive! The areas where I provided more focus though, is on specific flash points I see looming. Namely:
- Cloud wars. The owners of these LLM’s are going to battle it out to try to become the de facto standard, in the same way as Google established dominance in search engines two decades ago. This has already started.
- Very rapid disruptive impact on some industries. I am being transparent about where GPT-4 is helping me in this blog, but I needn’t be. So writing in general, and digital marketing as an example case at hand will be severely impacted. Same is true for coders. While I am writing this I am also asking GPT-4 to “Write me a python script to compile a summary of this week’s news about Large Language models, format it as an email, and send it to everyone in my CRM database.” I ran the script and it worked first time (although the email formatting was a bit too old school for my taste).
- A re-think of our education system. For a while educators will try to fight LLM’s, insisting it’s cheating which is perfectly true within our current framework. However, these things are not going away again, so there will need to be an accommodation and adjustment at some point. Out of interest, I asked my wife (an academic) to mark a Psychology essay written by GPT-4. She gave it 52% (a marginal pass) because it was one-sided in its analysis, the references were too dated, and it misrepresented and mis-cited some of the research.
- An Intellectual Property backlash. Having these models cannibalize and reformulate the original work they were trained on to produce something new, but similar, is likely to provoke a reaction and response from the very people who worked hard to create the material in the first place. We can expect to see artists and writers formulate methods for advertising that their content is not AI created, potentially creating two tiers of content in the future. Of course, there will also need to be adequate controls to prevent LLM’s harvesting content to use for training against an author or artist’s will.
Anyway, back to search.
How can LLM’s be used in search applications?
Pureinsights is a company with a multi-decade heritage in search, so of course the big question we have been asking is: where can we use this in search? As I’ve said, we don’t currently see LLM’s as being a replacement to search: there are dangers in allowing a model prone to hallucinations to become the arbiter of truth, and being able to ascertain and validate the credibility of a source is a very important aspect of researching a topic that should not be given up too readily. It also presents some tricky problems for intellectual property rights, echo chambers, and potential for bias.
Nevertheless, LLMs provide a wealth of possibilities for enhancing search in interesting ways, some of which Pureinsights are already doing. LLM’s can be employed to help with:
- Query understanding: LLM’s can be used to better understand the key aspects of and relationships in a query and therefore help optimize the way it is presented to the search engine.
- Semantic search: Vector search is already a part of many search engines to supplement or replace traditional keyword search. LLM’s can also help with intent detection to help reformulate and re-write queries.
- Questions and answers: At Pureinsights we use LLM’s to help implement Extractive Answers and Knowledge Graph answers.
- Multilingual search: As discussed earlier LLM’s can provide a cheap and easy way to get your search (or even your whole site) translated into multiple languages.
- Voice search: This has become fairly mundane now, but let’s not forget that the voice to text capabilities in your browser, apps and sites are driven by language models.
- Personalization: LLMs can be used to provide context to a query and thereby personalize the responses.
- Ranking and relevance: in the last decade LLM’s have already revolutionized the quality of search results on the public search engines, but companies are only just now being able to catch up and make use of it. We expect widespread adoption over the next few years.
So quite a bit of potential then!
Wrapping up
LLM’s are now sophisticated enough to make a real difference to a variety of industries and domains. The impact is likely to be large and wide-ranging, and so every business should consider how to leverage these technologies. They are also ready to be adopted to supercharge your search system.
Whilst LLMs are not an alternative to search engines, they do have a wide range of capabilities that have a bearing on search, including natural language understanding, question answering, sentiment analysis, content generation, text classification, data extraction, multilingual search, voice search, personalization, and improving ranking. These capabilities can all be brought bear to take traditional keyword-based search into a new era. So, it’s difficult to over-emphasize the significance of Large Language Models (LLMs) in the realm of search nowadays.
Having said all of that, we understand that it can seem a bit daunting and be difficult to know where and how to start. And that’s where we’re here to help. With decades of experience in search, and our Pureinsights Discovery Platform™ which is taking advantage of these advances, Pureinsights is perfectly placed to support you.
So, as always, feel free to CONTACT US with any comments or questions or to request a complimentary consultation to discuss your ongoing search and AI projects.
Cheers,
Matt
RELATED RESOURCES
Other Blogs in This Series
- What is ChatGPT? Search and AI Perspectives (Part 1 of 3)
- What is GPT-3 Search and AI Perspectives (Part 2 of 3)