A Powerful New NLP Technique for Enterprise Search Applications
With the disruption in information search and retrieval by AI, Pureinsights has promoted a hybrid model that limits the range of responses to your specific content while using AI as the “brains” to understand queries and your content. The industry seems to have settled on a name for this: Retrieval Augmented Generation (RAG).
RAG is a new approach to natural language processing (NLP) that combines the power of large language models (LLMs) with the precision of information retrieval systems. RAG models are trained on a massive dataset of text and code. They may even leverage existing general LLMs like Google BERT, Google Bard, or ChatGPT. But they also have access to an external knowledge base, which allows them to generate more accurate and informative responses.
Traditional LLM Queries vs RAG Query Models
In a traditional search application relying primarily on an LLM only (likely a 3rd party LLM), user queries are submitted to the LLM, which interprets the meaning and intent of the query, and then generates an answer from what the LLM knows.
We will illustrate this in an example of asking an LLM for a movie recommendation (see the video from MongoDB’s Ben Flast that inspired this).

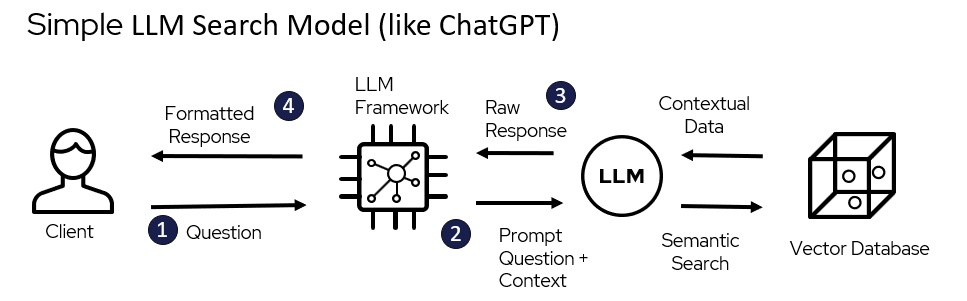
Simple LLM Query Model
We can see that a direct query to a generative LLM like ChatGPT results in an understandable, cohesive response. But maybe a better response is one that leverages additional information, like an up-to-date movie database.
Here is how the architecture flow might look for this type of query (below).
- The user submits a question or query to an LLM framework. This is a developer toolset, such as LangChain or llamaindex, that allows users to interact with LLMs.
- The LLM framework formulates a prompt with the right context and submits it to the LLM. The LLM then performs a semantic search on its vector database. This means that the LLM searches for documents in its database that are semantically similar to the prompt.
- The vector database returns the contextual results to the LLM, which sends a raw response or answer back to the LLM framework.
- The LLM framework formats the response and sends it back to the user.
But LLMs are like black boxes. This means that:
- They only know what they have been trained on.
- They don’t source their answers.
- They may make up answers (hallucinate).
- They can’t answer questions using knowledge outside of their training data.
In other words, LLMs are powerful tools, but they are not perfect. They can only answer questions based on the information they have been trained on, and they may not always be accurate. It is important to be aware of these limitations for architectures that only query LLMs directly.
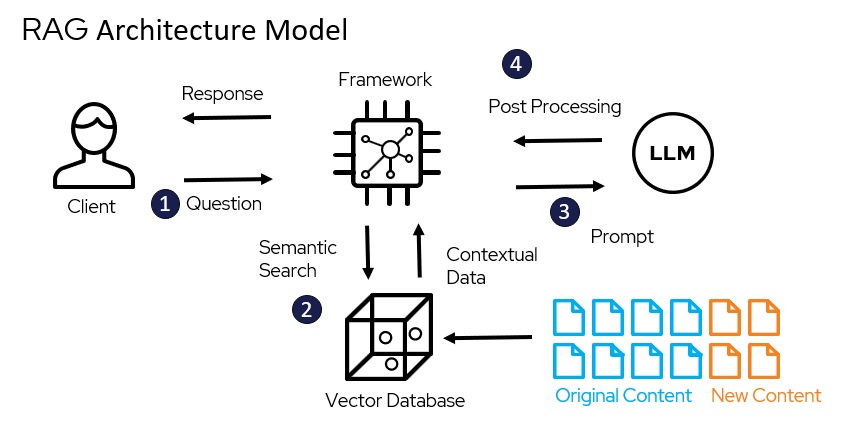
Retrieval-Augmented Generation Query Model
In a RAG model, the LLM is first used to interpret the meaning and intent of the query. Then, the LLM is instructed to retrieve related content from one or more specific content stores. This allows us to leverage the LLM and a vector database to generate and answer questions from additional content, which can yield better results than using an LLM alone.

- The user submits a natural language question or query.
- The RAG framework performs a semantic search of a vector database containing embeddings from the specified data sources (which can be updated with new content).
- The contextual results (or “answers”) are returned and submitted as a prompt to the LLM, which “speed reads” the answer.
- The LLM’s response is then processed and sent to the framework, which formulates a response to the user. In the RAG model, the response is also likely to provide a link to some or all of the related source documents for the answer, similar to what keyword search applications provide.
A RAG model works by first using the LLM to understand the query. Then, the LLM uses this understanding to retrieve relevant information from a database. The LLM then generates a response based on the retrieved information and sends the answer back to the user, ideally with links to the source documents.
One Step Better : RAG+ for Hybrid Search
We believe that future user search experiences will require a hybrid approach, combining traditional keyword search with smarter, AI-driven responses. As your CTO, Phil Lewis likes to say, “LLMs have a problem responding to a non-question”, which could include a keyword search like “Red Nike shoes.”
An improved architecture for this might look like this:
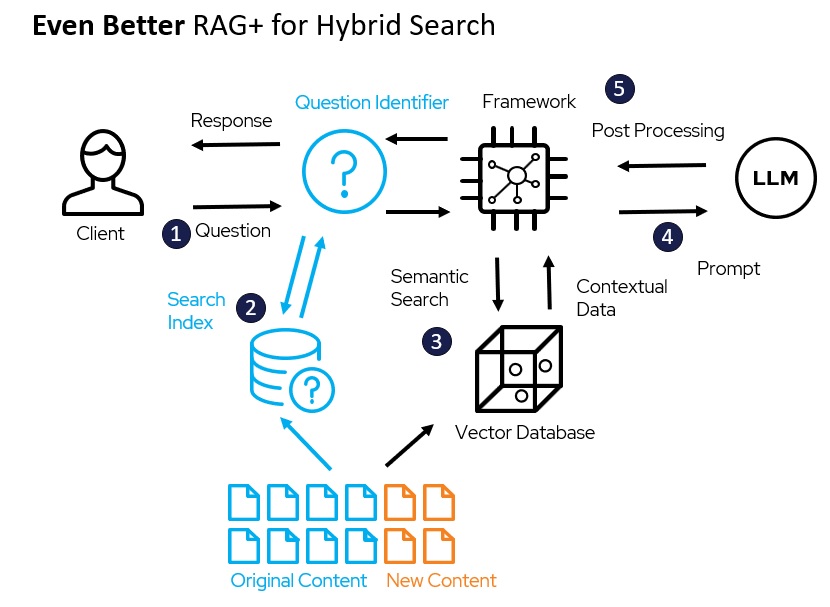
- The user asks a question or query.
- The system determines if the query is a simple keyword search or a more complex question. If the query is a simple keyword search, the system performs a traditional search and returns the results to the user.
- If the query is more complex, the system performs a semantic search of the vector database. This means that the system searches for documents in the database that are semantically similar to the query.
- The system then sends the semantic search results to the LLM. The LLM “speed reads” the results and generates a response.
- The system then processes the LLM’s response and formulates an answer for the user.
Note that in this example, your original content or data stores can be used to populate both the traditional search index for keyword search and the vector database used in AI-driven semantic search. RAG models also help address information security, in that your content never has to go beyond your firewalls (though its contextual data might), and you are able to maintain the same level of information security as in traditional search systems down to the specific document.
RAG is an Advantageous Extension of LLMs
The simplest definition of RAG is that it is an architecture for leveraging the power of LLMs to securely answer questions about your enterprise content.
RAG models have a number of advantages over traditional LLMs, including:
- Improved accuracy: RAG models are less likely to produce hallucinations or make factual errors, because they can ground their responses in the external knowledge base.
- Improved security: RAG models don’t require that you expose your content to train the LLMs; you have much better control over data access like you would in your own traditional search application.
- Increased domain expertise: RAG models can be customized to specific domains by using domain-specific knowledge bases. This makes them ideal for enterprise applications, such as customer service chatbots or legal research tools.
- Enhanced auditability: RAG models can track which sources they used to generate each response, making it easier to audit their outputs.
RAG is a powerful new NLP technique that has the potential to revolutionize the way we interact with computers. It is especially well-suited for enterprise applications, where accuracy, domain expertise, and auditability are all critical.
Use Cases for Retrieval Augmented Generation
Here are some specific examples of how RAG can be used in an enterprise setting:
- Customer service chatbots: RAG-powered chatbots can provide customers with more accurate and helpful answers, even if their questions are complex or open-ended.
- Legal or Scientific Research tools: RAG can help lawyers or scientific users find and understand documents related to their legal cases or scientific research.
- Technical support chatbots: RAG-powered chatbots can help IT teams to troubleshoot technical problems more quickly and accurately.
- Knowledge Management tools: RAG can enhance the user experience in any type of search or intranet tool for knowledge workers.
- Content generation tools: RAG can be used to generate high-quality marketing copy, product descriptions, and other types of content.
Retrieval Augmented Generation (RAG): A Promising New NLP Technique for Search and AI
Retrieval Augmented Generation (RAG) is a new NLP technique that has the potential to revolutionize the way we interact with information. RAG models combine the power of large language models (LLMs) with the ability to access and process large amounts of data. This makes them ideal for search applications, as they can provide more comprehensive and informative answers to our questions.
RAG models also solve a number of important challenges in search, including:
- Knowledge security: RAG models can be used to ensure that the information presented accurately and reliably, and only to authorized users.
- Recency: RAG models can be used to keep search results up-to-date with the latest information.
- Sourcing: RAG models can be used to identify and cite the sources of the information that they present.
- Prevention of “hallucinations”: RAG models can be used to prevent LLMs from generating inaccurate or misleading information
As RAG models continue to develop and mature, we can expect to see them used in even more innovative and groundbreaking ways. If you are interested in learning more about how RAG models can be used to improve your search and AI solutions, please CONTACT US for a free initial consultation.