
Matt Willsmore
Running Large Language Models (LLMs) is expensive – it requires a lot of compute power and the current boom is creating shortages in hardware, pushing prices up. There’s a new company called Groq (not to be confused with Elon Musk’s Grok) who are starting to make waves in this space by developing a new architecture optimized for LLM inference, so we decided to take a look.
CPU to GPU to TPU to LPU?
LLM inference is the process of getting a response from a trained large language model (LLM) for a user’s query or prompts. It relies on processing units like CPUs, with ongoing research to make them more efficient for this demanding task.
There’s a new PU (Processing unit) on the block, and it could be set to case some waves amongst those of use using and advising on the use of Large Language Models (LLMs). But before we get into it, let’s take a step back to look at the evolution of these things.
Once upon a time you could run your compute on a CPU, a central processing unit, and that was that. Everything ran on CPU’s, and some were faster than others. As an occasional gamer, I still remember in the mid to late nineties when the 3Dfx Voodoo and ATI Rage graphics cards came along with dedicated GPUs (graphics processing units) which offloaded the highly parallel processing required for rendering all the polygons needed for videogames, especially 3D video games.
I was just starting my career in search at this point and didn’t see any correlation. Fast forward a decade or so to the early 2010s and one of my colleagues sent an article around to all the techies about how a group of researchers had figured out how to train ML models using GPUs which made them an order of magnitude faster. This would make a new breed of neural networks (what we now call deep learning) models possible.
Early breakthroughs in deep learning, particularly image classification, paved the way for transformer models just a few years later. These models revolutionized Natural Language Processing (NLP), significantly impacting Google’s workload, which relied heavily on NLP tasks.
Recognizing this shift, Google engineer Jonathan Ross noticed the surge in matrix calculations on Google’s TensorFlow framework. During his 20% dedicated project time, he played a key role in developing the Tensor Processing Unit (TPU), specifically optimized for these calculations. This innovation, like the transformer models before it, led to significant performance gains, enabling the creation of advanced Generative AI models like ChatGPT.
However, a key challenge with these models is their reliance on sequences, both for input and output. The order of words is crucial. For instance, ChatGPT generates text one token (word unit) at a time, using the previous word to predict the next. This sequential nature inherently limits processing speed, even on highly optimized parallel processing architectures.
Recognizing this bottleneck, Jonathan Ross and his team, now at Groq, developed a new solution: the Language Processing Unit (LPU). Unlike traditional architectures, LPUs are specifically optimized for the unique processing needs of generative AI models, paving the way for significant speed improvements.
What is an LPU?
The Language Processing Unit (or LPU) is a revolutionary processing system designed to accelerate inference for sequential tasks like those in AI language applications (LLMs). It tackles two key LLM bottlenecks: compute density and memory bandwidth. By boasting superior compute power for LLMs compared to GPUs and CPUs, LPUs significantly reduce the time needed to process each word, leading to much faster text generation. Additionally, LPUs eliminate external memory limitations, further enhancing performance over GPUs.
While optimized for deploying pre-trained models rather than training from scratch, the LPU seamlessly integrates with popular frameworks like PyTorch and TensorFlow, allowing you to leverage readily available LLM models.
LLM Inference Performance Impact
So how much faster is it?
For those of us very familiar with the wait times for a GenAI, using Groq is a real head turner. I would recommend giving it a try yourself because it is quite jaw dropping. As you can see below, my request hit 500 tokens a second. So, my request for a 500-word summary took just over a second! Although the response streams back, it’s so fast it barely needs to.

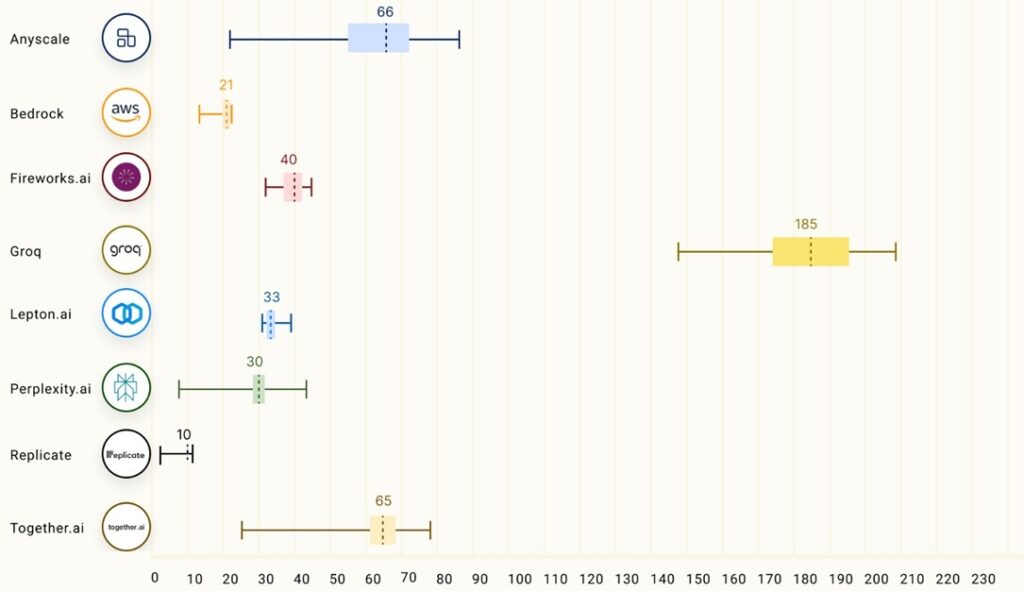
In independent benchmarks Groq demolish the competition with their response being around 18x faster on average:
Tokens per second 70B parameter model:
Time to First Token (TTFT)
The other metric to consider is responsiveness which is measure as time to first token (so lower is better). Groq has the second lowest mean time to first token at 0.22s but has less variance than the fastest. Again, an impressive result.
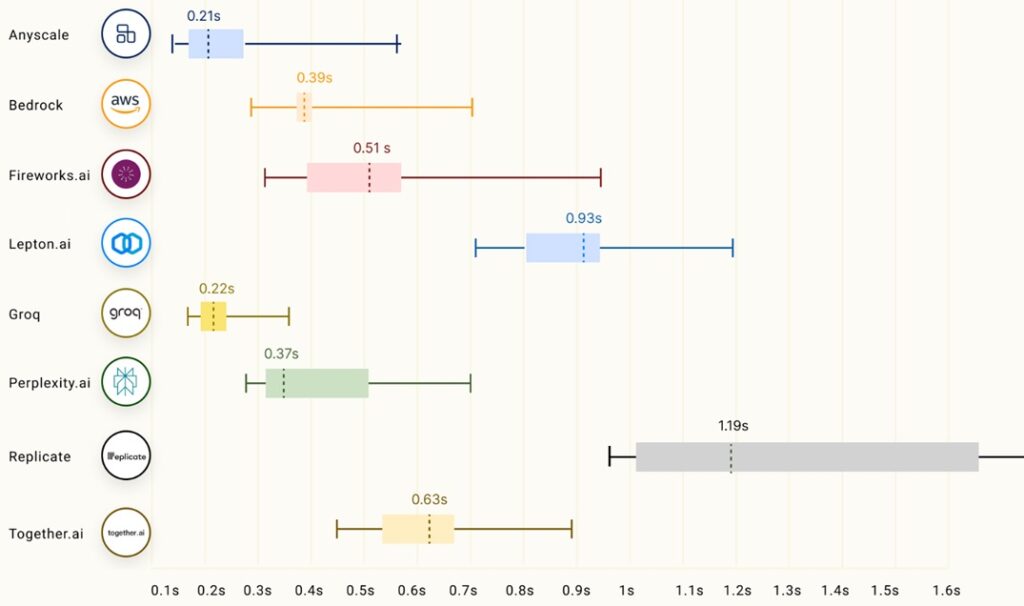
Metric Source: https://github.com/ray-project/llmperf-leaderboard?tab=readme-ov-file
So why does this matter?
I have heard some of our clients say that they like the streaming response and they are not bothered that it takes a little time to complete. In fact, I have heard it said that some would artificially introduce a lag if necessary so you can still read along! And that’s fine, it’s a user experience decision. The real advantage of a fast response is that it opens up new possibilities. For example, you could:
- Have the LLM generate a response, then review it to choose areas to improve and then iterate so that it optimizes and proofreads its own outputs.
- Agent based workloads where the LLM formulates a multi part plan and then executes it, adjusting the plan based on each step to reach an outcome become much less cumbersome if the wait time for each step is measured in milliseconds.
- Speech to AI interfaces. Of course this is already possible, converting audio to text and then feeding that to the LLM is relatively trivial, but at speed it is possible to have a real time conversation. For an example take a look at this CNN clip on Groq (jump to around 3:30 if you are in a hurry.)
Wrapping Up: LLM Inference Will Get Faster, Cost Less
So, it looks like 2024 might be the year where LLMs get much faster at inference as the hardware adapts to this critical workload. This is a fast-moving area of focus in the industry right now, and we expect the bigger players to enter the market too. It will mean that in time the cost of LLM inference will come down too because the hardware architecture is a better fit and better suited. Keeping up with all of these changes can be time consuming so if you need some advice, we’re happy to help. With decades of experience as consultants in search and our Pureinsights Discovery platform, which takes advantage of the latest advances in search, including RAG and Knowledge Graphs, Pureinsights is perfectly positioned to support you.
So, as always, feel free to CONTACT US with any comments or questions or to request a complimentary consultation to discuss your ongoing search and AI projects.
Cheers,
Matt