
Graham Gillen
In the world of large language models (LLMs), a revolutionary concept has emerged: 1-bit LLMs. Developed by a team at Microsoft Research Asia, 1-bit LLMs promise significant advancements in efficiency and accessibility. But what exactly are they, and how could they change the game?
The concept of 1-bit LLMs was developed by a team of researchers at Microsoft Research Asia, including Furu Wei and Shuming Ma They created BitNet, the first 1-bit QAT method for LLMs, which achieved state-of-the-art results in natural language processing tasks while reducing memory usage and energy consumption.
Traditional vs. 1-Bit LLMs
Traditional LLMs:
Traditional LLMs work like powerful software that analyzes every tiny detail of an image or text, requiring a lot of processing power and storage space.
1-Bit LLMs: A New Approach
1-bit LLMs take a different approach, considering only basic information and making them much faster and less demanding on resources. While they can still recognize the overall picture, they miss finer details.
Visualizing the Analogy
The adjacent images perfectly illustrate the analogy. The image on the left, representing traditional LLMs, boasts a high-quality resolution of 300 pixels per inch (PPI) but requires a substantial 180kB of storage space. By contrast, the image on the right, representing 1-bit LLMs, has a lower resolution of 72 PPI, but requires only a fraction of the storage space – a mere 10kB.
Despite the significant reduction in resolution, the subject remains recognizable as a flower, highlighting the tradeoff between detail and efficiency. This visual comparison demonstrates how 1-bit LLMs achieve efficiency gains by sacrificing some detail, while still maintaining essential functionality.

Performance Comparison
In their research, the team at Microsoft Asia ran exercises to compare the performance of their 1-bit LLM (BitNet b1.58) to a traditional LLM (FP16 Llama). They compared the perplexity score of each LLM (how well the model predicts a given text) at different model sizes (number of parameters or size on input data), while measuring performance in terms of the latency (ms) and memory requirements (GB) of the models.
According to the researchers, “BitNet b1.58 starts to match full precision LLaMA LLM at 3B model size in terms of perplexity, while being 2.71 times faster and using 3.55 times less GPU memory. This is illustrated in Table 1 below drawn from the research paper (Image Credit).
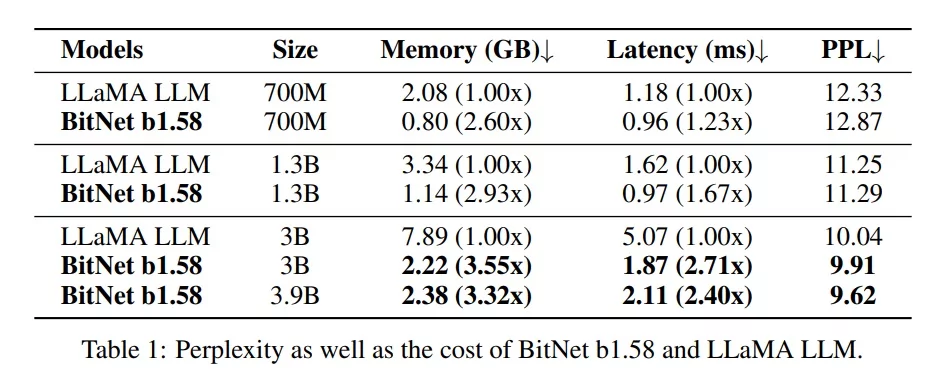
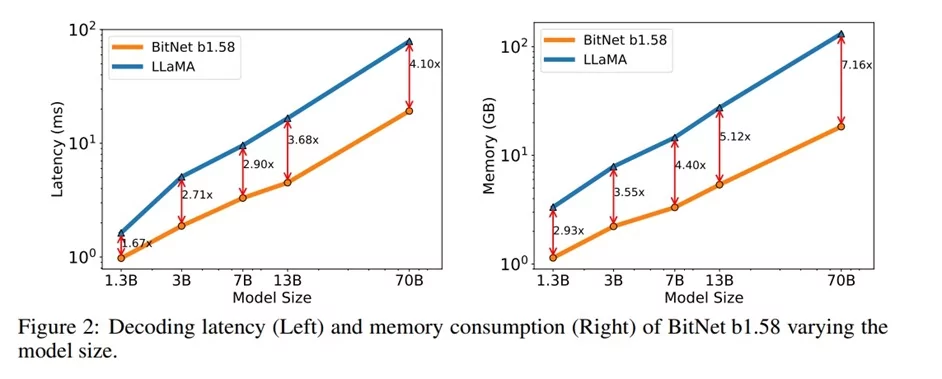
The Trade-Off
While 1-bit LLMs are efficient, they come at a potential cost. Traditional LLMs can achieve greater accuracy and nuance, and researchers are striving to strike a balance between efficiency and performance.
Comparison Example: Sentiment Analysis
Let’s look at an example of how using traditional vs. 1-bit LLMs might differ in a sentiment analysis use case.
Regular LLM:
Imagine a sentiment analysis LLM trained on a massive dataset of reviews with assigned sentiment labels (positive, negative, neutral). Here’s a breakdown of some possible parameters involved:
- Word Embeddings: Each word in a review gets converted into a multi-dimensional vector representing its meaning and sentiment tendencies. These vectors are learned during training, with positive words having vectors closer to a “positive” region in the multi-dimensional space and vice versa.
- Hidden Layer Weights: The LLM has multiple hidden layers where complex calculations occur. Weights associated with these connections determine how strongly positive or negative sentiment from word embeddings gets propagated through the network.
- Sentiment Scores: During training, the LLM learns to map the final output of the network to a specific sentiment score. This score could be a probability distribution (e.g., 80% positive, 10% neutral, 10% negative) or a single value on a scale (e.g., -1 for negative, 0 for neutral, +1 for positive). These scores are compared to the labeled sentiment of the training data for adjustments.
1-bit LLM:
1-bit LLMs operate on a much simpler principle for sentiment analysis. Here’s how it might work:
- Binary Sentiment Embeddings: Instead of complex multi-dimensional vectors, words are assigned a single bit value (1 or 0) based on their overall sentiment tendency learned during training. Positive words might be assigned 1, negative words 0.
- Threshold Activation: The LLM processes the sequence of these single-bit values. Each bit contributes positively or negatively (depending on its assigned value) towards a final score. A threshold (e.g., if the sum of positive bits exceeds a certain value) determines the overall sentiment (positive or negative) for the review.
Trade-offs:
While 1-bit LLMs are efficient, they come at a potential cost. Traditional LLMs can achieve greater accuracy and nuance, and researchers are striving to strike a balance between efficiency and performance.
1-Bit LLMs: Powerful and Compact, But More Complex
Despite their apparent shortcomings, 1-bit LLMs have benefits like efficiency, deployment ease, and lower power consumption. However, they also introduce added complexities like accuracy challenges and training complexity.
Benefits
- Efficiency: Reduced memory usage and faster computations due to simpler operations.
- Deployment: Easier to deploy on hardware with limited resources (e.g., IoT devices, smartphones).
- Energy Consumption: Lower power consumption, which is critical for battery-powered devices.
Challenges and Limitations
- Accuracy: The primary challenge is maintaining model accuracy. The reduction in precision can lead to a significant drop in performance compared to full-precision models.
- Training Complexity: Training 1-bit models requires specialized techniques to handle the binary constraints while still effectively learning from data.
Applications: When to Consider 1-Bit LLMs
1-bit LLMs are particularly useful in scenarios where resource efficiency is critical. For instance, they can be used in mobile applications, real-time data processing on edge devices, and other environments where computational resources are limited but rapid inference is required.
In summary, a 1-bit LLM is a neural network model optimized for efficiency by reducing the precision of its weights and activations to a single bit. While offering significant benefits in terms of speed and resource usage, it also presents challenges in maintaining accuracy and requires specialized training techniques.
While still under development, 1-bit LLMs hold promise for various applications:
- Internet of Things (IoT): Imagine smart devices with built-in 1-bit LLMs capable of real-time data analysis and decision-making.
- Voice Assistants: 1-bit LLMs could power next-generation voice assistants that are faster, more responsive, and usable on low-power devices.
- Edge Computing: 1-bit LLMs could be deployed on edge devices for tasks like anomaly detection and local data processing, reducing reliance on centralized cloud resources.
The Potential of 1-Bit LLMs
The single-bit architecture of 1-bit LLMs opens doors for exciting possibilities:
- Enhanced Efficiency: Imagine running an LLM on a mobile device without draining the battery! 1-bit LLMs have the potential to be incredibly efficient, making them perfect for deployment on edge devices with limited resources.
- Widespread Accessibility: The computational simplicity of 1-bit LLMs could significantly reduce the cost and energy requirements for training and running them. This paves the way for broader adoption of LLMs across various industries and applications.
- Novel Hardware Design: The unique bit structure of 1-bit LLMs opens doors for designing specialized hardware specifically optimized for their operations. This could further enhance their efficiency and performance.
Towards Smaller LLMs
Just as with traditional LLMs, your use case may not dictate having to create your own LLM from scratch. Your application may deploy a new pre-built 1-bit LLM, or you may incrementally train an existing one to better suit your needs.
One final point is that this research on 1-bit LLMs had shed light on the utility of smaller, more lightweight LLMs. By using some of the techniques used to create 1-bit LLMs from larger models (using a technique called quantization), you may see vendors introduce more “lightweight” versions of excellent open-source LLMs like Llama 3.
Summary: What this Means for Your Business
1-bit LLMs are not a replacement for traditional LLMs where complexity and nuanced understanding are required. However, they are excellent candidates for AI deployed “at the edge”. Consider cost effectiveness when choosing technologies and developing deployment and operational plans.
While efficiency and cost effective may drive many technology decisions, we always think it’s best to start with the problem that you are trying to solve. Then consider cost effectiveness when choosing technologies and developing deployment and operational plans.
- 1-Bit LLMs will NOT replace traditional LLMs where complexity and nuanced understanding is required. For example: language translation, legal document reviews, or medical diagnosis support.
- The logic applies to generative AI applications like script writing, or poetry and song writing.
- Or applications where “explainability” important, like scientific research or financial analysis.
However, due to their computational efficiency (both in storage and compute requirements), they are excellent candidates for AI deployed “at the edge”:
- Intelligent wearable devices (for health and other monitoring)
- Intelligent sensors (security monitoring, safety monitoring, etc.)
- Lightweight voice assistants (in cars or on a phone when internet connectivity is not available)
This rules out most of our customers in the knowledge retrieval application space. However, you can never discount where technology may lead in the future.
For example, we are working with one customer in the automotive space who is implementing a use case for diagnosing engine problems by having the customer record and upload engine noise to an application that can compare the sound to thousands of records of known engine problems and their related sounds. In the future, it may be possible to deploy noise monitors and 1-bit LLMs directly to the vehicle, providing the owner with an early warning of a potential problem.
We hope you enjoyed this brief overview of 1-bit LLMs. The changes in the AI space can still make your head spin. If you have any further questions or need help on an AI or search project, please CONTACT US.
Additional Resources
- 1 Bit LLM (Large Language Model) | Explained in 1 Minute (youtube.com)
- The Original Research Paper: The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
- 1-bit LLMs Could Solve AI’s Energy Demands – IEEE Spectrum
- LLM Inference Speed Revolutionized by New Architecture – Pureinsights
- What are Large Language Models? Search and AI Perspectives – Pureinsights